
Le scraping vous permet d’extraire de la donnée d’un site internet afin de la traiter localement. L’intérêt du scraping est de pouvoir manipuler, traiter, enrichir ses données. Il est possible de scraper tous éléments présents sur le web, numéro de téléphone, mail ou simplement des éléments html. Le scraping est une tâche ingrate et longue. C’est pour cela, qu’une grande majorité des growth hackers font appel à l’automatisation. Nous allons voir ensemble comme nous pouvons scraper de la donnée utilisable de manière automatisé. Nous allons créer un scraper en ruby qui ira scraper les données que nous lui indiquons sur un url précis de manière automatisé.
Pour commencer :
Pour commencer nous allons créer note dossier pour notre scraper. Dans ce dossier nous allons créer un fichier scraper.rb.
Avant de nous lancer dans notre code, nous allons avoir besoin de deux gems ruby pour effectuer notre scraper.
- Open-uri est une gem permettant de lire et de récupérer le html d’une page
- Nokogiri va nous permettre de parser de la donnée html précédemment récupérer grâce à Open-uri
En premier lieu nous allons configurer notre fichier scraper en appelant les gems nokogiri et open uri installé sur notre espace de travail.
require 'nokogiri'
require 'open-uri'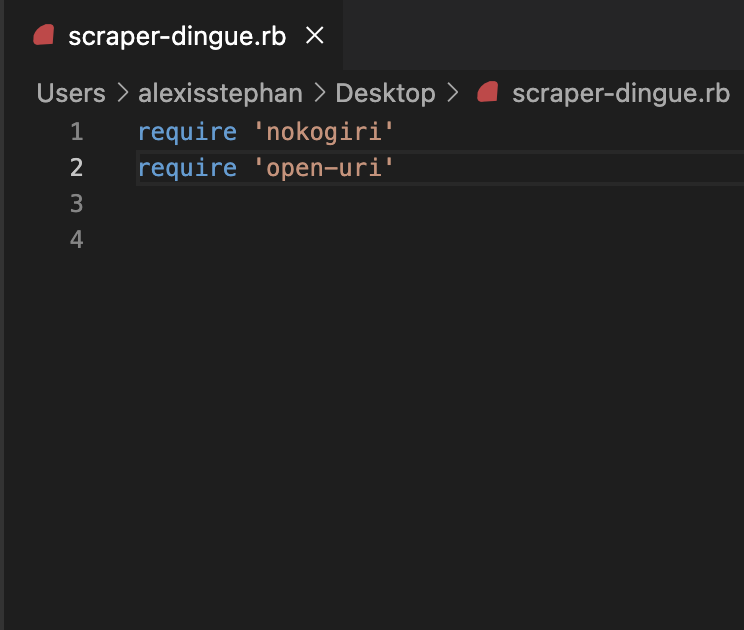
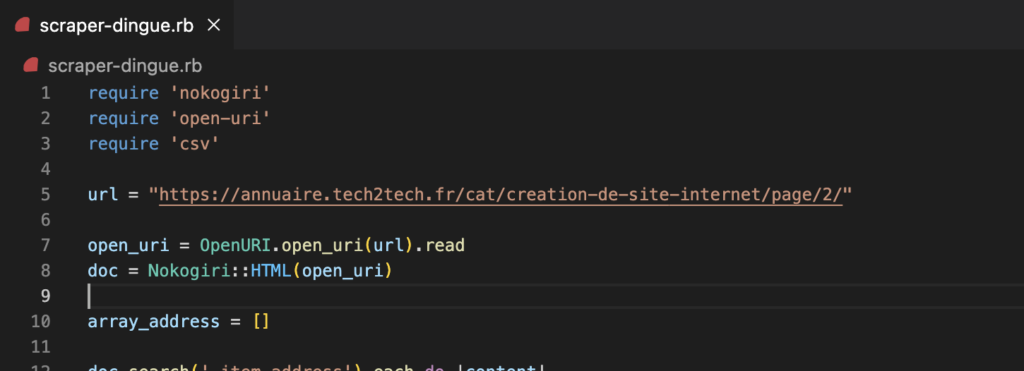
Dans un second temps, nous allons avoir besoin de stocker l’url que nous souhaitons scraper dans une variable. Pour notre exemple nous allons scraper cet url ainsi que les pages suivantes : https://annuaire.tech2tech.fr/cat/creation-de-site-internet/page/2/
url = "https://annuaire.tech2tech.fr/cat/creation-de-site-internet/page/2/"Utiliser Open-uri pour lire la page html
Maintenant que nous avons notre url dans une variable, nous allons pouvoir dans un premier temps, utiliser notre gem Open-uri pour venir lire la page. Pour cela nous ajoutons cette ligne :
open_uri = OpenURI.open_uri(url).read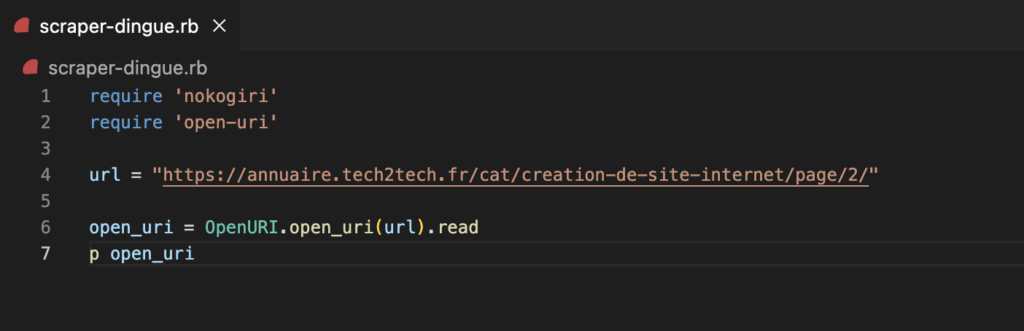
Nous passons en argument notre variable contenant notre url. Il est possible de mettre dans les parenthèses directement l’url souhaité. Mais nous souhaitons rendre notre url dynamique car nous avons plusieurs pages à scraper. La méthode .read permet de venir tout le contenu de la page (en l’occurence le html).
Je vais vous afficher notre ligne de code afin de mieux comprendre les objects que nous manipulons.
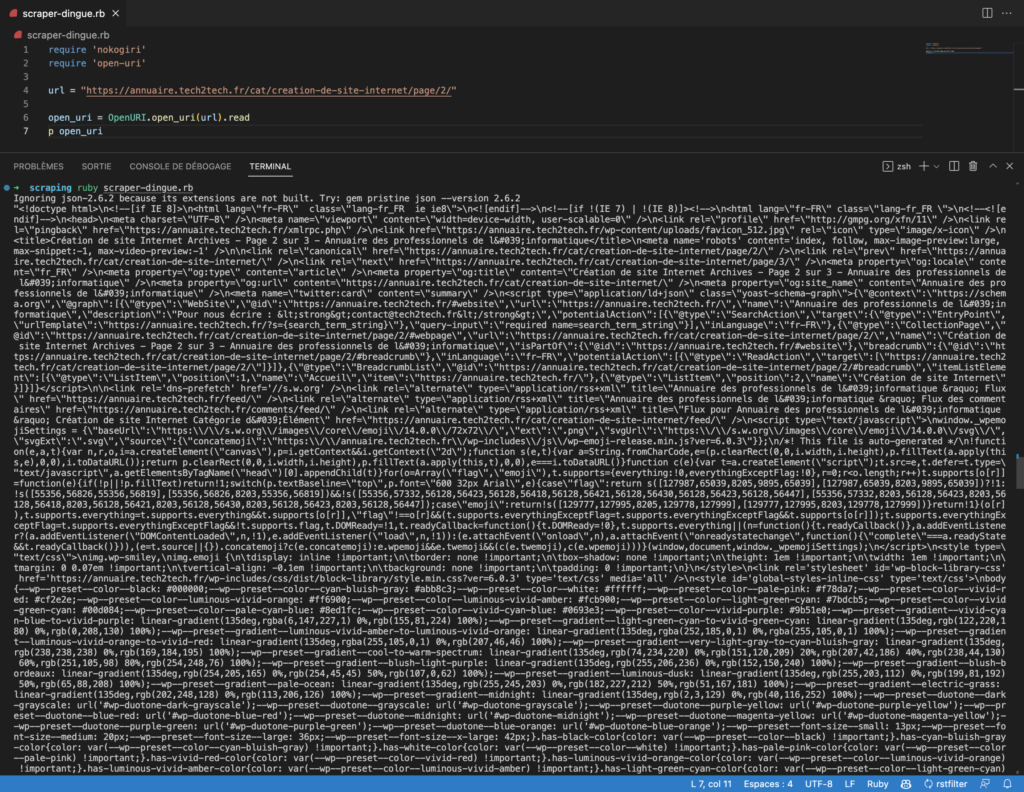
Nous pouvons voir que notre terminale nous renvoie le contenu html. C’est la exactement la même chose que si nous allions sur notre url et que nous affichons le code source de la page.
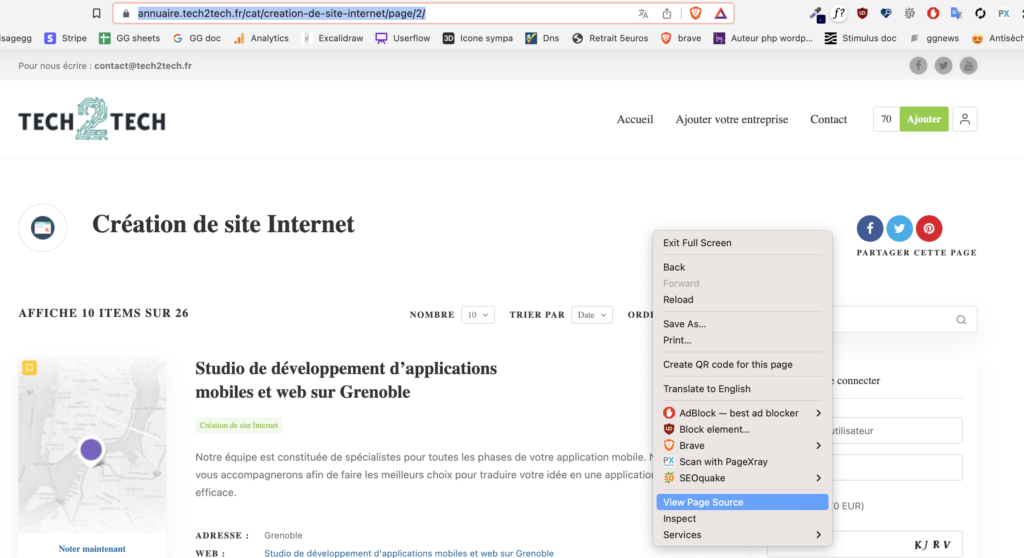
Comparez votre résultat fait manuellement avec votre terminale, vous verrez que le contenu est identique. C’est juste le formatage de sorti des données du terminale qui diffère légèrement.
Utiliser Nokogiri pour parser le HTML de notre page
Maintenant que nous avons récupérer le html de notre page avec open-uri, nous allons pouvoir utiliser Nokogiri pour venir parser notre donnée.
Pour utiliser Nokogiri sur notre résultat nous allons ajouter ces lignes de codes :
doc = Nokogiri::HTML(open_uri)Commencer notre scraper
Pour automatiser le scraping de toutes les informations contenant l’adresse, ainsi que le service donnée sur notre page html, nous allons devoir effectuer une itération sur notre bloc. Ce qui nous permettra de sortir autant de fois que la valeur est contenue dans notre document.
Pour cela nous allons utiliser la méthode search de ruby sur notre variable contenant notre contenu parser via Nokogiri.
doc.search('METTRE NOTRE SELECTEUR CSS').each do |content|
end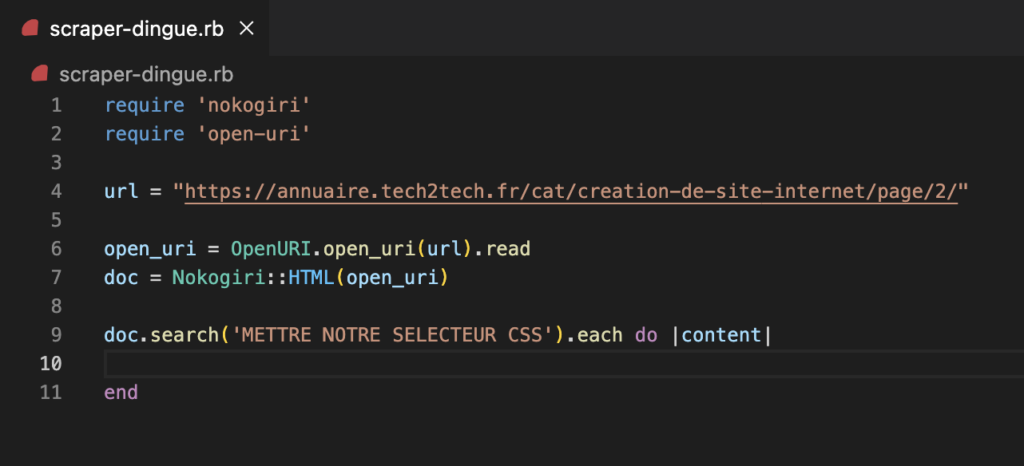
La méthode search prend un argument. Qui sera en l’occurence la class css qui contient le résultat de la donnée que nous souhaitons scraper. Pour identifier la class, nous allons aller sur notre url et inspecter le code source afin d’identifier le selecteur css que nous allons utiliser.
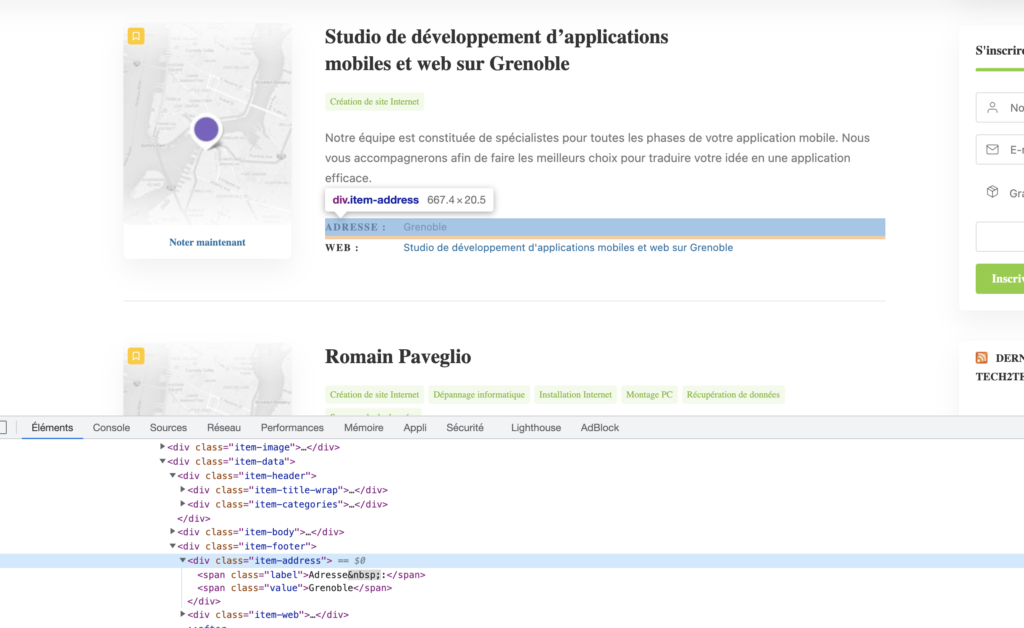
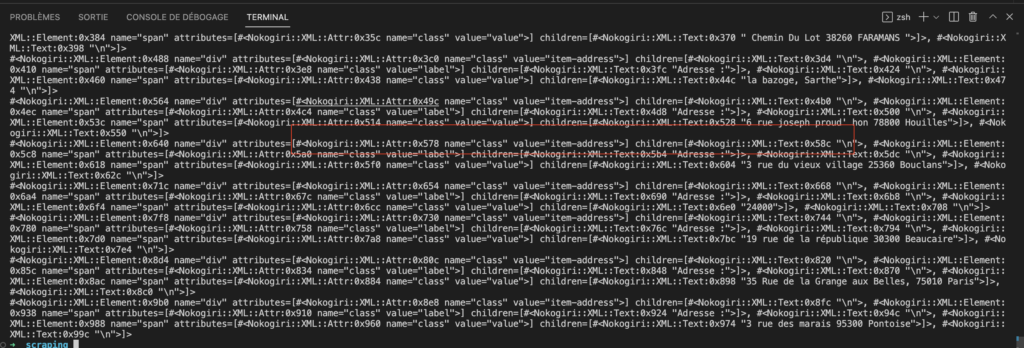
Nous pouvons voir que l’adresse est contenu, dans une div parente ayant la class : item-address dans laquelle nous avons deux span avec le label et sa valeur. Nous allons alors utiliser comme sélecteur css :
.item-address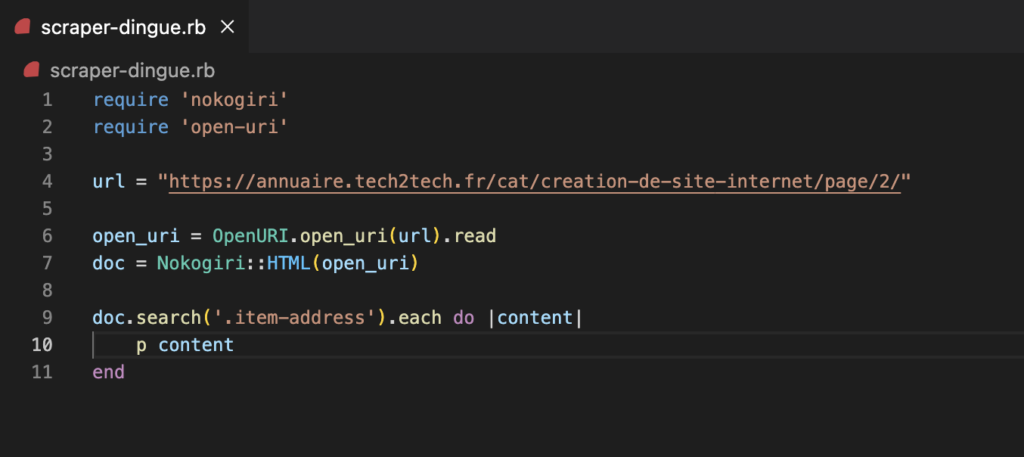
Tester notre résultat en affichant en terminale :
Nous cherchons à avoir le texte contenu dans la div que nous avons inspecter sur la page. Pour cela nous allons modifier le coeur de notre itération pour ajouter la méthode .text (petit tips, pour cleaner votre donnée ajouter la méthode .text.strip. Cela vous permettra de faire un clean de la donnée ressortie.)
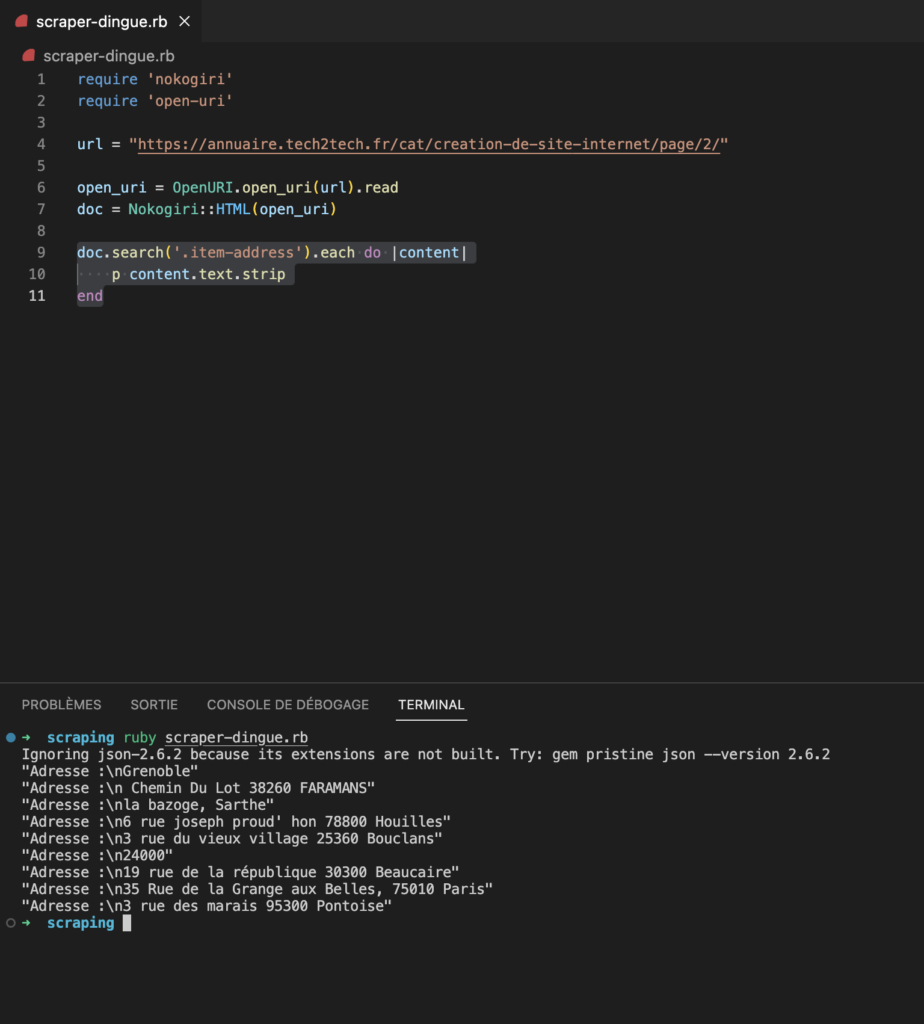
doc.search('.item-address').each do |content|
p content.text.strip
end
Testons notre code en lançant ruby nameoffile.rb :
Stocker notre donnée
Si vous en êtes ici, BRAVO ! vous avez déjà réussi à récupérer les données que vous souhaitez. Maintenant nous allons devoir les stocker dans un fichier csv afin de pouvoir le partager, traiter, filtrer nos données facilement.
Dans un premier temps, nous allons le stocker dans un array (tableau en français) qui par la suite va venir incrémenter notre csv.
Pour cela nous allons stocker un array vide dans une variable, puis venir l’incrémenter dans notre itération :
array_address = []
doc.search('.item-address').each do |content|
array_address << content.text.strip
end
Affichons notre résultat :
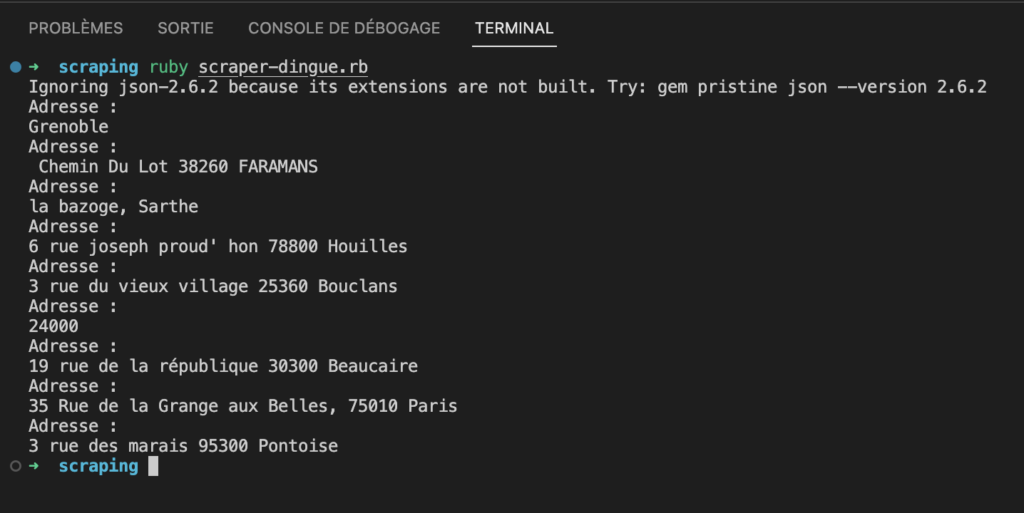
Stocker notre array dans un tableur csv
Maintenant que nous stockons nos données dans notre array, nous allons vouloir persister cette donnée dans un csv afin de pouvoir récupérer et surtout persister convenablement nos données.
Pour cela nous allons devoir utiliser le CSV. En ruby lorsque vous manipulez un csv, vous devez :
require 'csv'C’est le même principe que pour nokogiri et open-uri :
Codons maintenant la méthode de persistance de notre csv :
CSV.open ("scraper_fou.csv", "wb") do |csv|
csv << array_address
end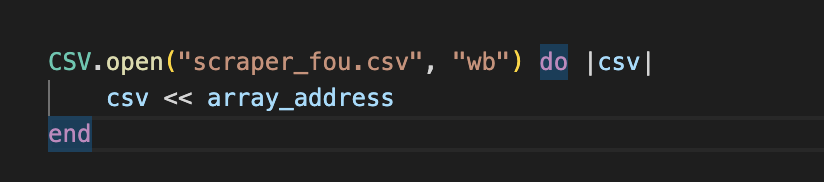
Nous appelons la class CSV avec la méthode open qui prend deux arguments : le filepath de note csv, ainsi que la méthode d’écriture. Pour notre exemple nous utiliser wb (write binary). Vous pouvez utiliser par exemple ab qui différente. Pour en savoir plus voici la doc sur les csv en ruby : DOCUMENTATION
Testons notre programme :
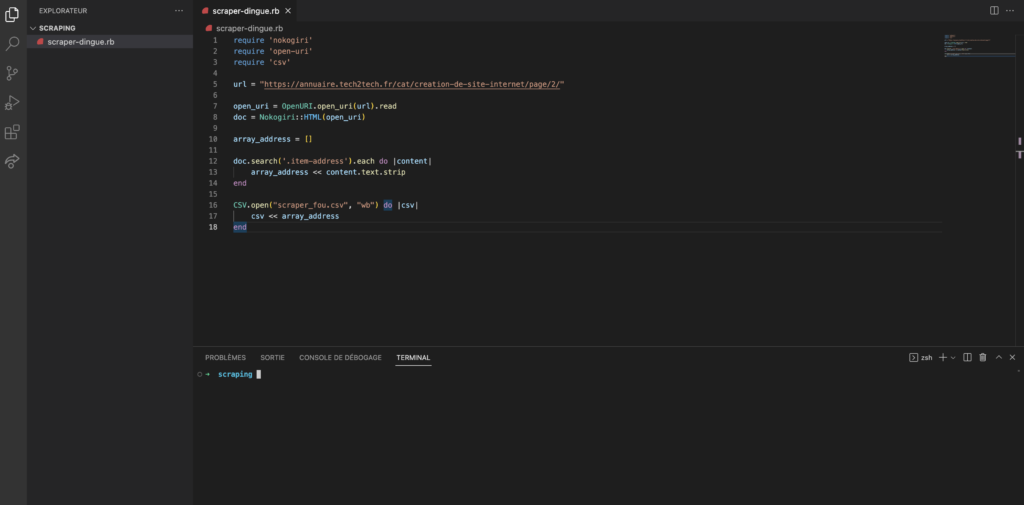
Nous allons lancer notre programme et voir ce qu’il se passe. Avant de lancer le programme voici mon vscode :
ruby name.rb # pour lancer votre programmeRésultat après avoir lancer notre programme :
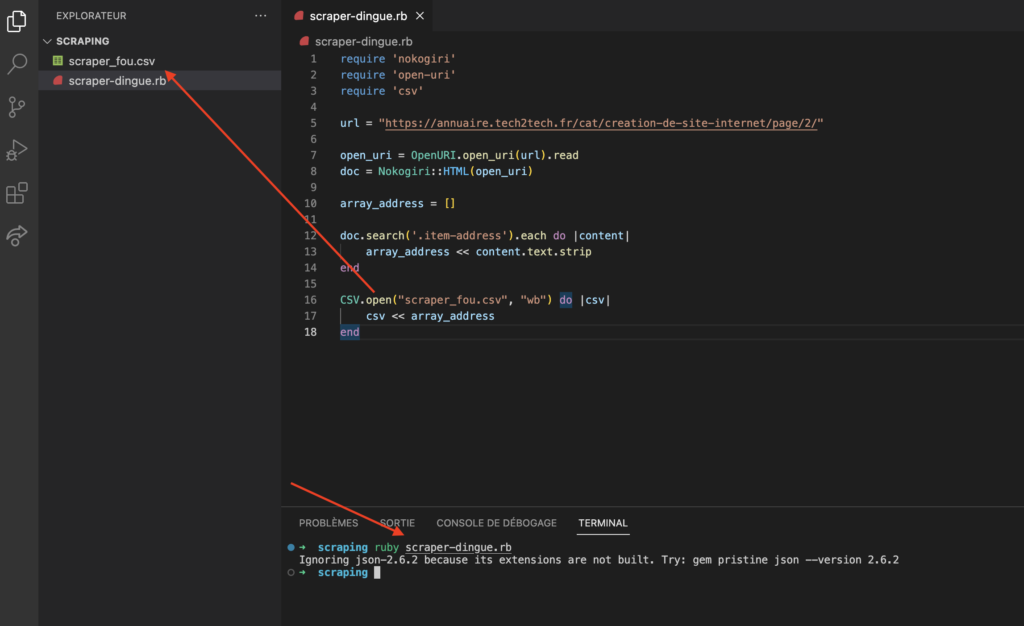
Nous pouvons constater que notre programme nous a bien créé notre CSV !! Allons voir immédiatement le résultat du stockage :
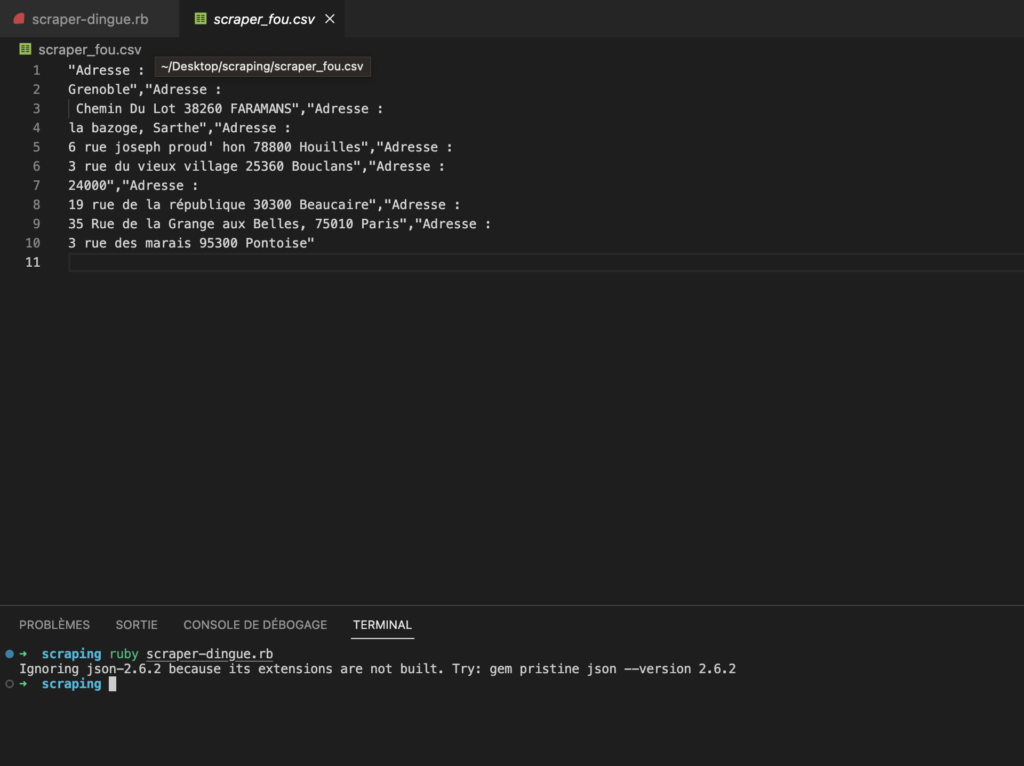
Parfait !
Optionnel : Complexifier notre scraper pour aller de page en page
Maintenant que nous voyons que notre scraper arrive à scraper la donnée demandée. Nous allons vouloir renouveler l’opération sur autant de page que le site en contient.
Pour cela nous allons définir un compteur à 0, devoir ajouter un boucle afin de réitérer l’opération autant de fois que nous l’avons décider.
Dans un premier temps, nous voyons que la structure de notre url est formée de cette façon : https://annuaire.tech2tech.fr/cat/creation-de-site-internet/page/2/
Nous allons pouvoir interpoler notre compteur dans l’url pour modifier la valeur de la page à chaque fois que notre scraper à récupérer les données souhaités sur l’url.
Voici le résultat final :
require 'nokogiri'
require 'open-uri'
require 'csv'
compteur = 2
array_address = []
while compteur != 4
url = "https://annuaire.tech2tech.fr/cat/creation-de-site-internet/page/#{compteur}/"
open_uri = OpenURI.open_uri(url).read
doc = Nokogiri::HTML(open_uri)
doc.search('.item-address').each do |content|
array_address << content.text.strip
end
p compteur
compteur += 1
end
p compteur
CSV.open("scraper_fou.csv", "wb") do |csv|
csv << array_address
end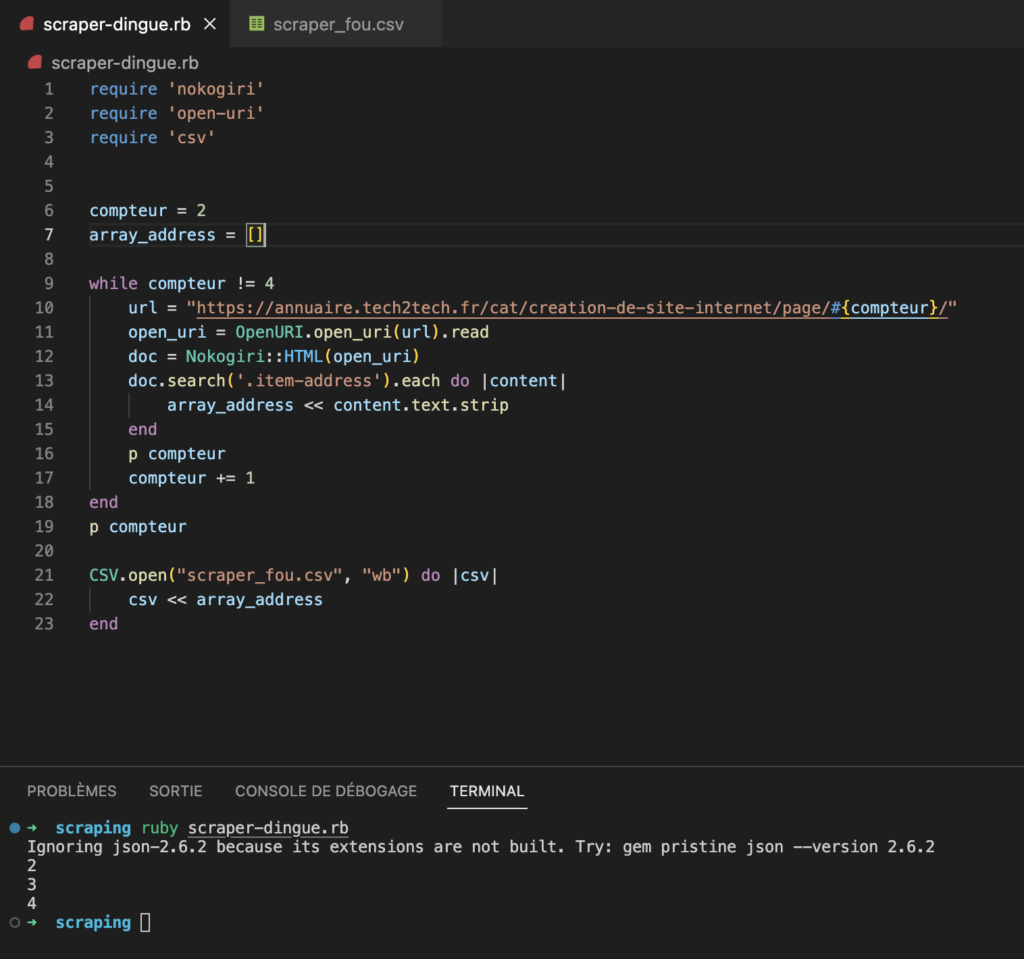
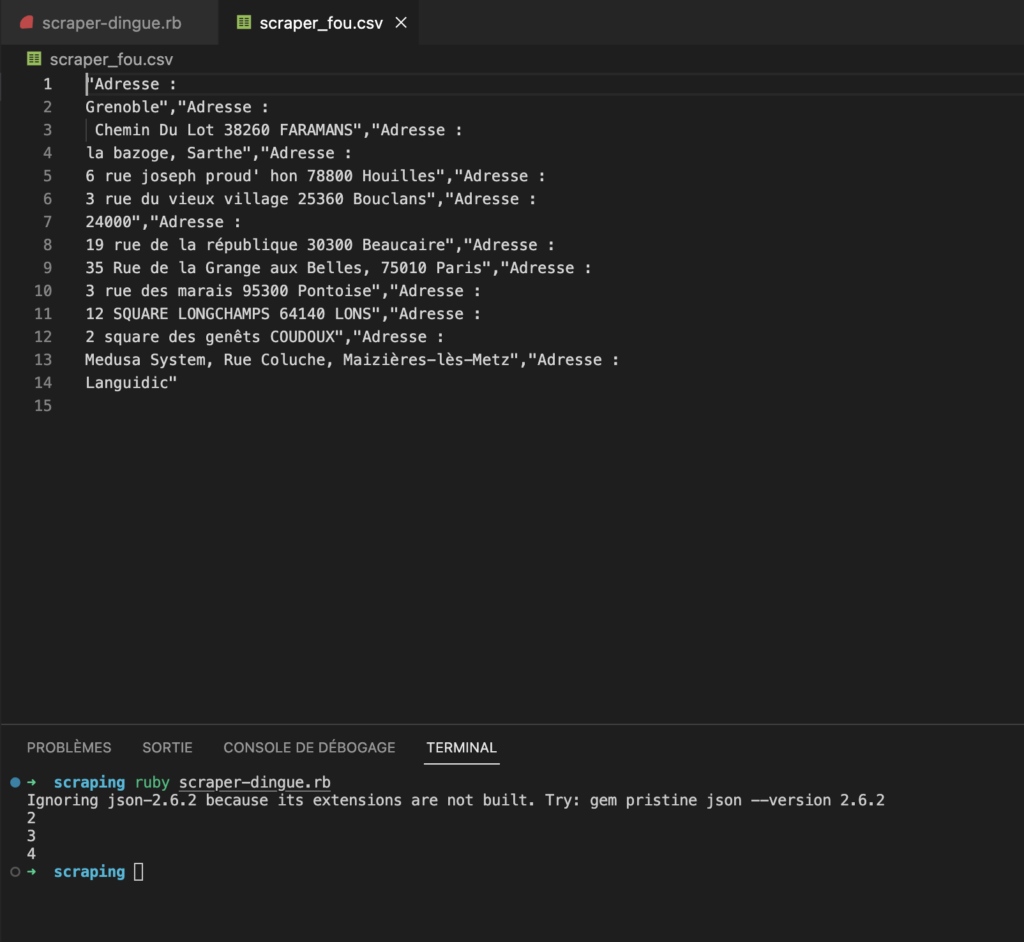
Nous avons réussi à scraper la page 2 et 3 du site que nous voulons !
Lien repo d’un scraper réalisé par AS WEB : https://github.com/alexisjps/scraper_fou